Use with Ollama
Ollama allows you to run LLMs on your local machine.
Refer to the Ollama documentation to get Ollama up and running.
Then follow the steps below to connect InfernoAI to Ollama.
1. Set OLLAMA_ORIGINS to *
Follow the steps for your operating system.
Mac
If Ollama is run as a macOS application, environment variables should be set using launchctl:
-
For each environment variable, call
launchctl setenv.Terminal window launchctl setenv OLLAMA_ORIGINS "*" -
Restart Ollama application.
Linux
If Ollama is run as a systemd service, environment variables should be set using systemctl:
-
Edit the systemd service by calling
systemctl edit ollama.service. This will open an editor. -
For each environment variable, add a line
Environmentunder section[Service]:[Service]Environment="OLLAMA_ORIGINS=*" -
Save and exit.
-
Reload
systemdand restart Ollama:Terminal window systemctl daemon-reloadsystemctl restart ollama
Windows
On windows, Ollama inherits your user and system environment variables.
-
First Quit Ollama by clicking on it in the task bar
-
Edit system environment variables from the control panel
-
Set
OLLAMA_ORIGINSto* -
Click OK/Apply to save
-
Run
ollamafrom a new terminal window
2. Add custom model in InfernoAI
Now that Ollama is allowing connections from any origin, add the Ollama model as a custom model in InfernoAI’s model settings.
Open the “Manage models” dialog in the bottom left.
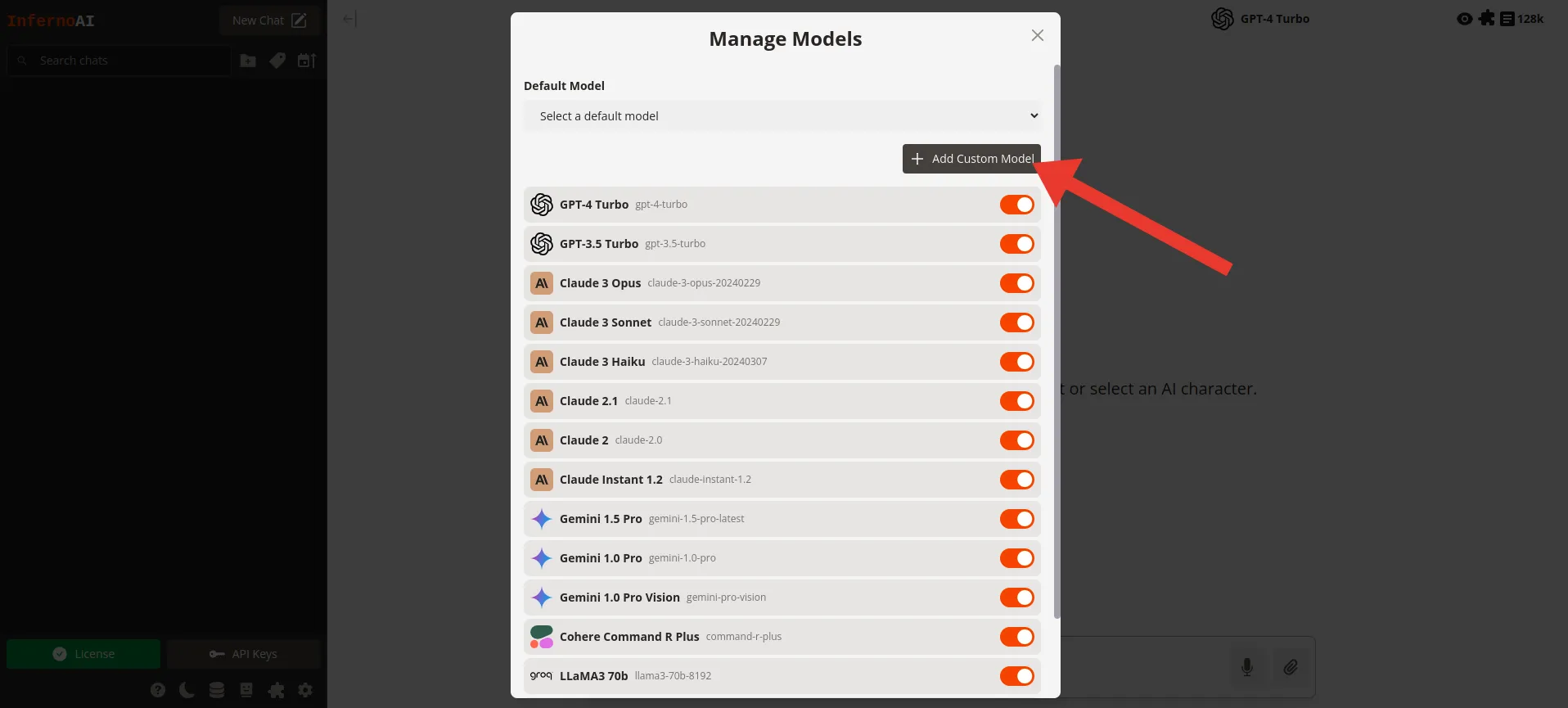
Click “Add custom model”
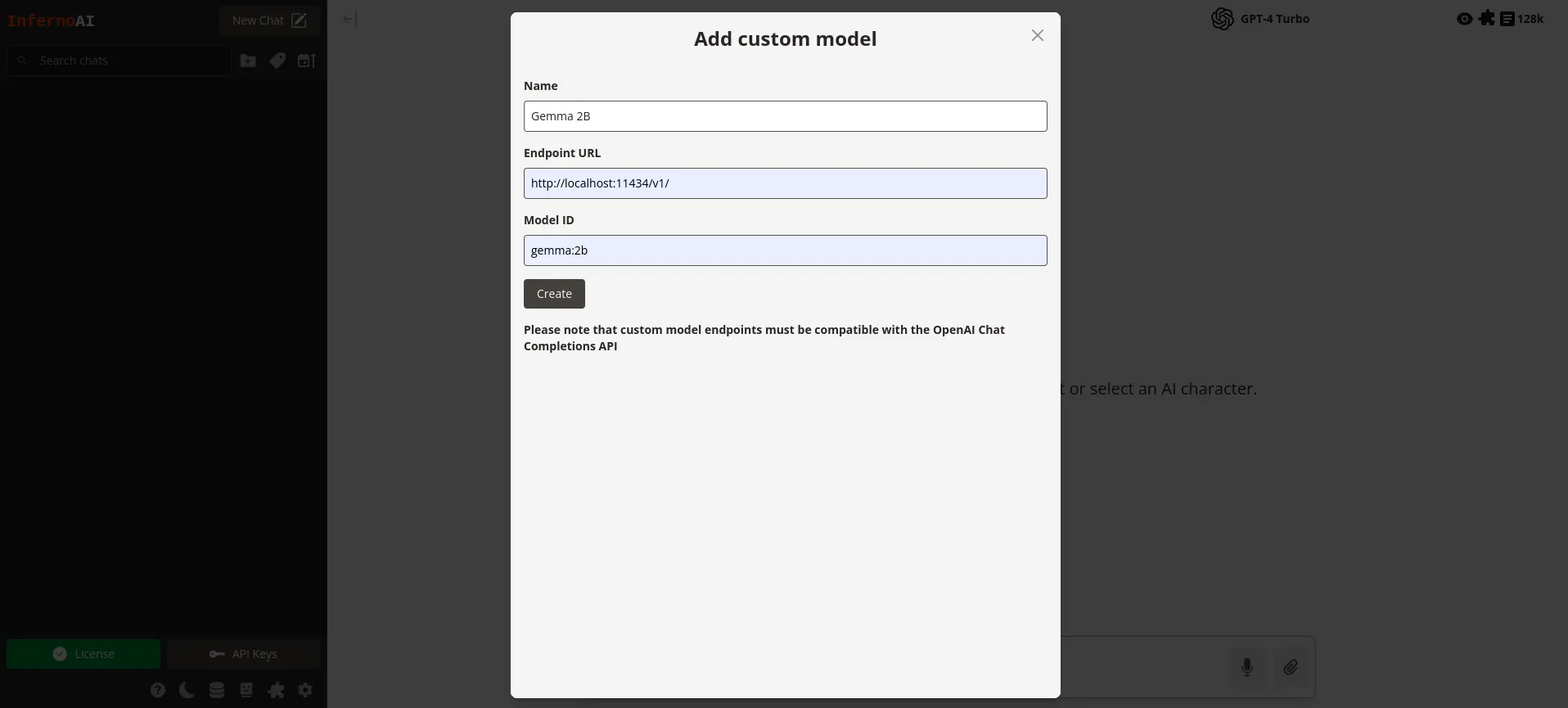
Complete the form:
- Name: A recognisable name for the model.
- Endpoint URL: The Ollama chat completions endpoint URL. By default this is https://localhost:11434/v1/
- Model ID: The exact ID for the model you want to access through Ollama.
Click “Create” and close the dialog. Now you can select the custom model in the models menu in the top right and start chatting.